
In the last post we looked at Q-Learning with respect to reinforcement learning; the idea that we can assess the quality of a particular state action pair and build up a cheat sheet that allows us to play the game proficiently.
Unfortunately we quickly came to the bottleneck in this problem; that as our state space grows, it becomes more and more computationally expensive to calculate the quality for every possible state action pair (that coupled with the fact that this only works on an environment that can be modelled with a Markov Decision Process). Instead of creating a Q-table (check out the previous post if you’re not familiar with Q-tables), we need a way to approximate the quality of an action without storing every possible combination of state action pairs.
Enter the good old neural network.
A neural network works like a blank brain that you can train to associate some input with some output. Give it 10,000 images of cats and dogs, along with the correct answers, and it will map the input to the output and be able to classify cat or dog on a new image that it hasn’t seen before. The caveat here is that you need to provide the correct answers during training. This means neural networks are a supervised learning problem.
Mathematically, we’re simply seeking to minimise the difference between the predictions from our neural net, and the actual correct answers. As long as there is a small error, our neural net will, on average, predict the same thing as the correct answer.
Enter our game for this post and our loss function…
Learning to play CartPole
Cart Pole is a game which ships with OpenAI’s gym library for reinforcement learning. It consists of a pole, hinged on a movable cart. The objective is simple; move the cart left or right to keep the pole balanced and upright.

But there’s a problem. With reinforcement learning, we seek to maximise our cumulative rewards over time. If we received a reward for moving the cart to the right to retain balance of the pole, then we may try moving the cart right again to get another reward. This unwanted behaviour is rampant in reinforcement learning and demonstrates how a simple oversight can turn good AI bad.
Instead of maximising reward, we want to maximise time. Our agent’s goal will be to keep the game going for as long as possible.
Experience Replay
Imagine we’re playing a game where our enemy pops out at either the right, or left of the screen. Each round is random, but suppose we get a large amount of rounds that favour one particular side. As our agent is trained sequentially, our neural net begins to favour that particular side and develops a bias in its prediction of future actions. In other words, we start to favour recent data and forget past experiences.
How do we train our neural net in a way that it doesn’t favour what it’s recently learned? How do we prevent our neural net from forgetting past experiences that may be relevant in the future?
The answer is surprisingly simple. We introduce the concept of experience replay, or memory. Every time we are exposed to a state action pair, we’ll store it away in an special python list type called a deque (it’s essentially a list of a fixed size, that removes the oldest element each time that you add a new one to it. That way we’ll have a constantly updating buffer of the last n number of state action pairs to train from).
With our experience replay buffer built up, we can randomly sample minibatches of experiences to train from and benefit from a wider look at our environment. Additionally, as our neural net gets better, so do the state action pairs that we train our neural net from. It’s a win win.
Building the CartPole Agent
We’ll start by importing our dependencies. Most of it is the same as last time, but we’ll use Keras for our neural net, and matplotlib for plotting our score over time.
import numpy as np
import gym
from keras import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
import matplotlib.pyplot as plt
from collections import deque
Next, we’ll build our agent. Note that this is all one class but I’ll try to break it up and talk about each method. Pay particular notice to the indentation here.
Our agent will take in the environment and hold the hyperparameters. We’ll use the env argument to determine our state size and action size.
class Agent:
def __init__(self, env):
self.memory = deque(maxlen=600)
self.state_size = env.observation_space.shape[0]
self.action_size = env.action_space.n
self.gamma = 0.95 # discount rate
self.epsilon = 1.0 # exploration rate
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.learning_rate = 0.001
self.model = self.build_model()
Notice in the initialisation of our agent, we made a call to a build_model() method. Let’s write that now to return our neural net from Keras. We’ll store this in a hyperparam so that we can make calls to predict actions or train it later.
def build_model(self):
model = Sequential()
model.add(Dense(24, input_dim=self.state_size, activation='relu'))
model.add(Dense(24, activation='relu'))
model.add(Dense(self.action_size, activation='linear'))
model.compile(loss='mse', optimizer=Adam(lr=self.learning_rate))
return model
Much like our previous tutorial, we’ll need a way to select an action based on our exploration / exploitation trade off. We’ll choose a random number between 1 and 0. If our number is greater than epsilon, we’ll use our neural net to predict which action we should take (exploitation), if it’s lower, we’ll select and action at random and continue to explore our environment.
def select_action(self, state):
# Selects an action based on a random number
# If the number is greater than epsilon, we'll take the predicted action for this state from our neural net
# If not, we'll choose a random action
# This helps us navigate the exploration/exploitation trade off
x = np.random.rand()
if x > self.epsilon:
# Exploitation
actions = self.model.predict(state)
return np.argmax(actions[0])
else:
# Exploration
return random.randrange(self.action_size)
Next we’ll introduce the idea of experience replay. We’ll write a very simple function that takes the state, action, reward, next_state, done data returned from taking an action on our environment, and adds it to the end of our deque (removing the oldest element at the same time)…
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
Lastly, we’ll need a function to train our neural net from our experience replay buffer. Firstly, we’ll make sure that we have enough experiences in our buffer to train from. If we don’t we’ll simply exit the function and keep exploring our environment until we do.
When we have enough experiences to sample from, we’ll take a random sample of experiences which we’ll call our minibatch, and use that to train the network by calculating our predicted Q-values.
Finally, we’ll reduce our epsilon to gradually nudge us more and more towards exploitation of our neural net in prediction our Q value, rather than exploring our environment by taking random actions.
def train_with_replay(self, batch_size):
# If we dont have enough experiences to train, we'll exit this function
if len(self.memory) < batch_size:
return
else:
# Sample a random minibatch of states
minibatch = random.sample(self.memory, batch_size)
# For each var in the minibatch, train the network...
for state, action, reward, next_state, done in minibatch:
# If we haven't finished the game, calculate our discounted, predicted q value...
if not done:
q_update_target = reward + self.gamma * np.amax(self.model.predict(next_state)[0])
else:
# If we have finished the game, our q-value is our final reward
q_update_target = reward
# Update the predicted q-value for action we tool
q_values = self.model.predict(state)
q_values[0][action] = q_update_target
# Train model on minibatches from memory
self.model.fit(state, q_values, epochs=1, verbose=0)
# Reduce epsilon
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
Training our Deep Q-Network
With our agent written, we’ll piece everything together and start training our deep Q-network. We’ll start by defining our cart pole environment and setting our environment specific hyperparameters like number of episodes and minibatch size. We’ll also keep track of our scores in an array in order to graph them out at the end.
env = gym.make('CartPole-v0')
episodes = 5000
max_steps = 200
batch_size = 32
agent = Agent(env)
scores = []
We’ll loop through our total number of episodes, and, in a smaller loop, step through our environment, taking actions and observing their rewards. We’ll add our observation to the experience replay buffer. At the end of our game, we’ll print our score, and train our agent on a random minibatch of experiences at the end of each episode.
for episode in range(episodes):
# Reset the environment
state = env.reset()
state = np.reshape(state, [1, 4])
score = 0
done = False
for step in range(max_steps):
# Render the env
#env.render()
# Select an action
action = agent.select_action(state)
# Take the action and observe our new state
next_state, reward, done, info = env.step(action)
next_state = np.reshape(next_state, [1, 4])
# Add our tuple to memory
agent.remember(state, action, reward, next_state, done)
state = next_state
score += 1
if done:
scores.append(score)
if episode % 500 == 0:
# print the step as a score and break out of the loop
# The more steps we did, the better our bot is
print("episode: {}/{}, score: {}".format(episode, episodes, score))
break
agent.train_with_replay(batch_size)
Graphing our scores
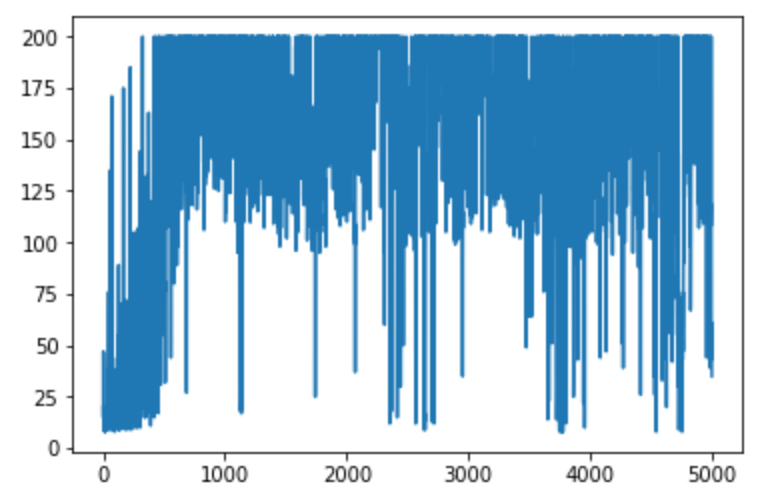
Finally, we can check how our agent performed over training by printing the score at each episode…
y = scores
x = range(len(y))
plt.plot(x, y)
plt.show()
Summary
We dealt with a larger state space by ditching our Q-table in favour of a neural network to approximate our Q-values of taking a particular action at a particular state. Our agent starts by exploring our space and very quickly learns to maximise its time playing the game. We navigated the problems in training our neural net by taking advantage of an experience replay buffer to stop our agent favouring recent experiences.
Deep Q Networks can be useful for exploring larger state spaces, but they also come with their own trade offs; mainly that we’re still using a very handy API to explore our environment. In future posts we’ll look at how we can handle more generic game spaces by building agents that can adapt to a wide variety of games.